
En janvier dernier, DeepSeek a surpris le monde entier en lançant un modèle d’IA de pointe à un coût nettement inférieur à celui de ses concurrents américains.
La sortie du DeepSeek-R1 a prouvé que la Chine pouvait rivaliser avec les plus grands dans le domaine du raisonnement de haut niveau.
Et comme je l’ai mentionné à l’époque, cela a également changé la trajectoire de la course à l’IA.
C’était un signe clair que Pékin voulait combler son retard sur les États-Unis, et cela prouvait que la Chine ne ralentissait pas.
Mais j’ai vu cela comme une bonne chose. Et je pense avoir eu raison. Car cela a finalement poussé les décideurs politiques américains à considérer l’intelligence artificielle comme une priorité nationale.
Je suis convaincu que c’est l’une des raisons pour lesquelles la Maison Blanche a récemment créé un nouveau plan de développement de l’IA interagences appelé Mission Genesis, qui pourrait représenter un projet Manhattan pour l’IA.
Et cela a certainement contribué à ce que le secteur privé investisse des milliards de dollars dans de nouveaux pôles de formation cette année.
Une initiative qui semble porter ses fruits.
ChatGPT-5 est arrivé cette année avec les meilleurs scores en matière de raisonnement à long terme. Google a récemment lancé Gemini 3 et a encore amélioré ses performances multimodales. Et Claude, d’Anthropic, est discrètement devenu le leader de la course à l’IA d’entreprise.
Mais cela ne signifie pas que DeepSeek est resté inactif.
La semaine dernière, la société a refait surface avec une nouvelle version appelée DeepSeek V3.2 et V3.2 Speciale.
L’annonce n’a pas choqué le monde comme celle de DeepSeek en janvier, mais les détails sont tout de même révélateurs.
Car si les chiffres publiés par DeepSeek sont exacts, la Chine vient de livrer son challenger le plus puissant à ce jour.
C’est donc le moment idéal pour faire le point avec DeepSeek.
Nouvelles revendications en matière de benchmark
DeepSeek affirme que son modèle V3.2 Speciale a obtenu des performances de niveau or dans quatre benchmarks académiques haut de gamme. Il s’agit notamment des Olympiades internationales de mathématiques (IMO) 2025, des Olympiades chinoises de mathématiques (CMO), des Olympiades internationales d’informatique (IOI) et des finales mondiales de l’ICPC.
Il est évident que ces tests ne sont pas simples.
Il s’agit des défis mathématiques et de codage les plus difficiles au monde, généralement dominés par des laboratoires de recherche d’élite. Les équipes américaines obtiennent souvent d’excellents résultats, mais elles publient rarement des modèles Open-Weight qui obtiennent les meilleurs scores.
DeepSeek affirme avoir réussi cet exploit.
La société a également révélé quelque chose d’inhabituel dans son rapport technique. Elle a déclaré que le modèle utilise un système appelé DeepSeek Sparse Attention pour traiter plus efficacement les problèmes à long contexte.
Elle a également déclaré que plus de 10 % de son budget informatique total avait été consacré à l’apprentissage par renforcement pour le raisonnement et le comportement agentique. C’est un chiffre inhabituellement élevé pour un modèle Open-Weight. Si cela s’avère vrai, cela expliquerait pourquoi DeepSeek présente V3.2 comme un modèle « axé sur le raisonnement » plutôt que comme un chatbot à usage général.
Voici comment la société présente son classement.
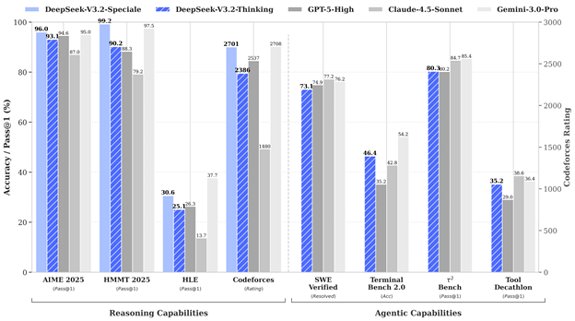
Comme vous pouvez le constater, les nouveaux modèles de DeepSeek semblent égaler ou se rapprocher des meilleurs scores obtenus par GPT-5 et Gemini 3 sur des tâches de raisonnement limitées telles que les mathématiques et la résolution de problèmes structurés.
Ces chiffres sont impressionnants, mais ils s’accompagnent d’une mise en garde importante.
Ils n’ont pas fait l’objet d’un audit indépendant. Tant que ce n’est pas le cas, nous devons les considérer comme des affirmations prometteuses plutôt que comme des avancées confirmées.
Cependant, certaines parties de cette version peuvent être confirmées.
Les pondérations sont disponibles en ligne et les développeurs ont déjà commencé à effectuer des tests d’inférence locaux. Les premiers utilisateurs affirment que le modèle gère mieux le raisonnement en plusieurs étapes que les versions précédentes de DeepSeek. Et le mécanisme d’attention clairsemée semble être réel d’après le code publié.
Mais le tableau devient moins clair lorsque l’on dépasse les scores en mathématiques et en codage.
Plusieurs groupes indépendants, dont une équipe de recherche qui collabore avec le NIST, ont testé les modèles DeepSeek précédents cette année. Ils ont conclu que ces versions restaient à la traîne par rapport aux meilleurs systèmes américains en termes de connaissances générales, d’utilisation des outils et de fiabilité dans le monde réel.
Ces conclusions ne contredisent pas les nouveaux chiffres de DeepSeek, mais elles soulignent un point important.
Obtenir de bons résultats à des concours de mathématiques ne garantit pas une intelligence générale. Cela montre simplement une force dans une partie d’un puzzle plus vaste.
Mais c’est l’intelligence générale qui compte à long terme.
C’est le même écart dont nous avons parlé en janvier. À l’heure actuelle, les entreprises américaines sont toujours en tête dans les domaines de la formation multimodale à grande échelle, des tests de sécurité mondiaux et du déploiement de plateformes intégrées.
OpenAI dispose du meilleur système d’utilisation des outils en production. Google possède l’architecture de mémoire la plus développée. Anthropic affiche les meilleurs résultats en matière de fiabilité et de stabilité du raisonnement. Et ensemble, ces entreprises ont accès aux plus grands clusters de formation de la planète.
DeepSeek est toujours à la poursuite de ces entreprises. Mais cela ne signifie pas que l’écart reste aussi important qu’auparavant.
Le nouveau modèle de DeepSeek progresse à un rythme qui aurait semblé irréaliste il y a seulement un an. Et le fait qu’il puisse fournir des modèles Open-Weight avec des scores mathématiques proches de la perfection devrait inquiéter tous ceux qui pensent que les États-Unis peuvent se permettre de se reposer sur leurs lauriers.
Car chaque fois que la Chine progresse dans le domaine de l’IA, elle met la pression sur les États-Unis pour qu’ils avancent encore plus vite.
Mon avis
DeepSeek affirme avoir formé V3.2 à l’aide de plus de 1 800 environnements synthétiques et de plus de 85 000 prompts. Il s’agit notamment de tâches de recherche, de codage et d’agent en plusieurs étapes.
Le comportement agentique est la prochaine grande étape de l’IA. Les modèles capables de raisonner, de planifier et d’agir de manière autonome façonneront tout, du développement de logiciels à la sécurité nationale.
C’est pourquoi je continuerai à suivre de près DeepSeek.
Car l’entreprise affirme qu’elle continuera à développer son pipeline agentique. Et si elle maintient cette trajectoire, nous pouvons nous attendre à des modèles encore plus ambitieux en 2026.
Cela signifie que les États-Unis doivent continuer à avancer à leur rythme.
Nous disposons toujours des entreprises d’IA les plus performantes au monde. Mais cette annonce envoie un message clair : la course à la superintelligence artificielle (ASI) est aujourd’hui plus proche qu’elle ne l’était en janvier.
Et les deux camps le savent.
À très vite,
Ian King

